Coherent Reconstruction of Multiple Humans from a Single Image
*Equal contribution
Coherent Reconstruction of Multiple Humans from a Single Image
Abstract
In this work, we address the problem of multi-person 3D pose estimation from a single image. A typical regression approach in the top-down setting of this problem would first detect all humans and then reconstruct each one of them independently. However, this type of predic- tion suffers from incoherent results, e.g., interpenetration and inconsistent depth ordering between the people in the scene. Our goal is to train a single network that learns to avoid these problems and generate a coherent 3D reconstruction of all the humans in the scene. To this end, a key design choice is the incorporation of the SMPL parametric body model in our top-down framework, which enables the use of two novel losses. First, a distance field-based collision loss penalizes interpenetration among the reconstructed people. Second, a depth ordering-aware loss reasons about occlusions and promotes a depth ordering of people that leads to a rendering which is consistent with the annotated instance segmentation. This provides depth supervision signals to the network, even if the image has no explicit 3D annotations. The experiments show that our approach outperforms previous methods on standard 3D pose benchmarks, while our proposed losses en- able more coherent reconstruction in natural images.
Video
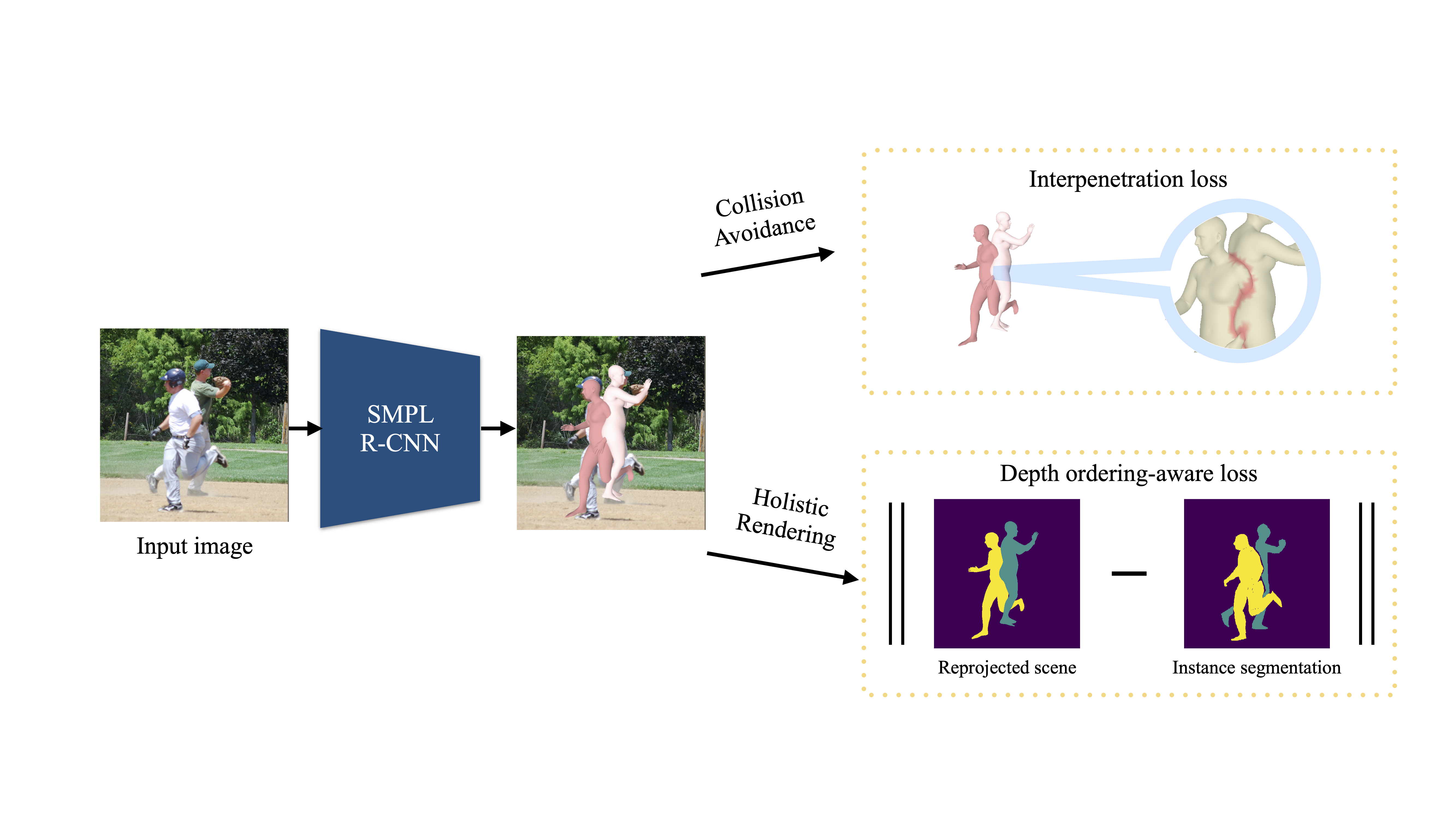
Overview
We use an end-to-end top-down approach. Our model follows the R-CNN paradigm. We augment Faster-RCNN with a SMPL parameter regression branch. To reconstruct humans, we use the detected bounding box to sample from the corresponding region of the shared feature map. Our key novelty is the introduction of two novel geometric losses.
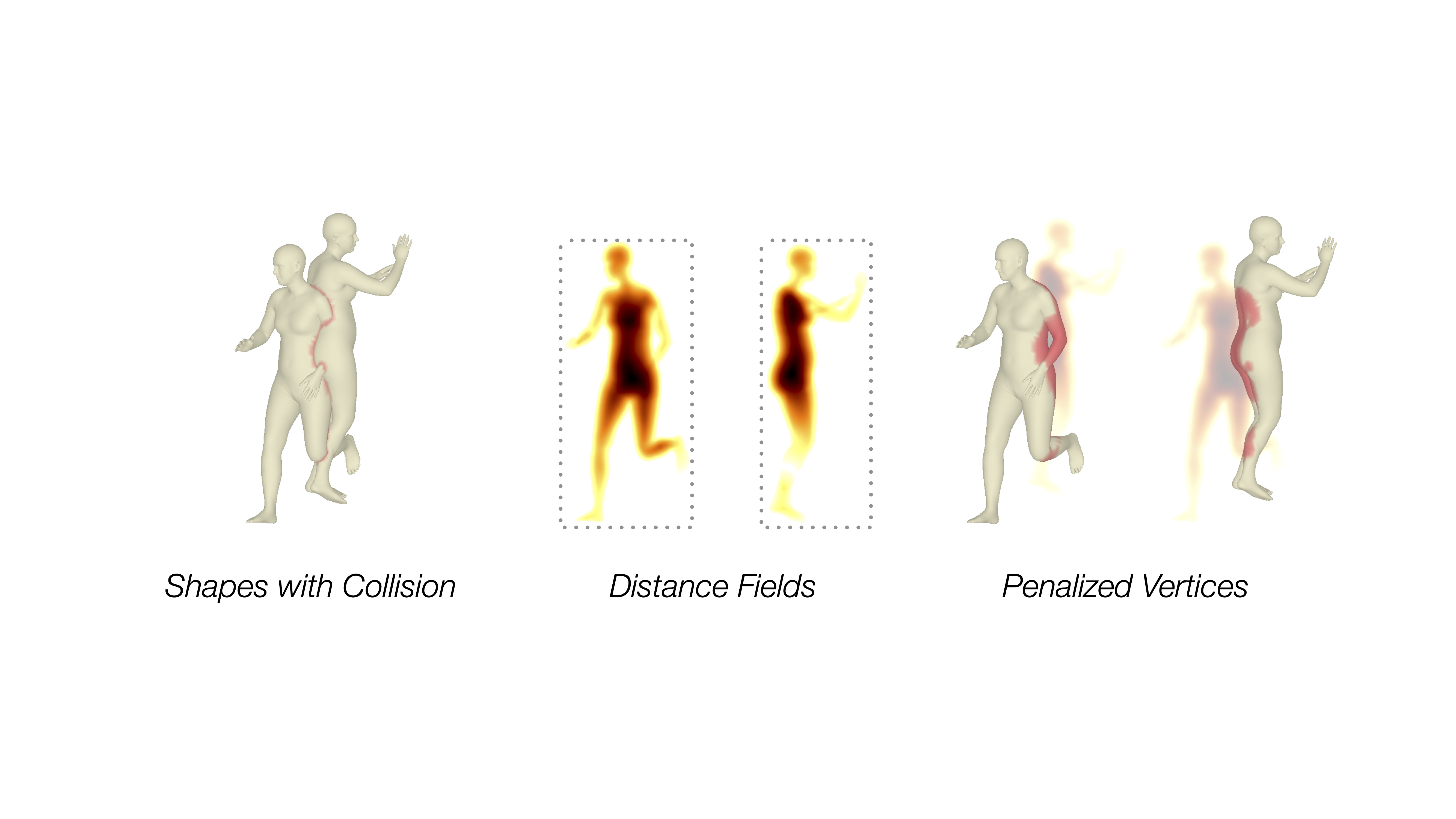
First, we penalize interpenetrations among the reconstructed people using a distance field-based loss. This loss function requires no additional annotations and encourages the network to regress meshes that do not overlap with each other.
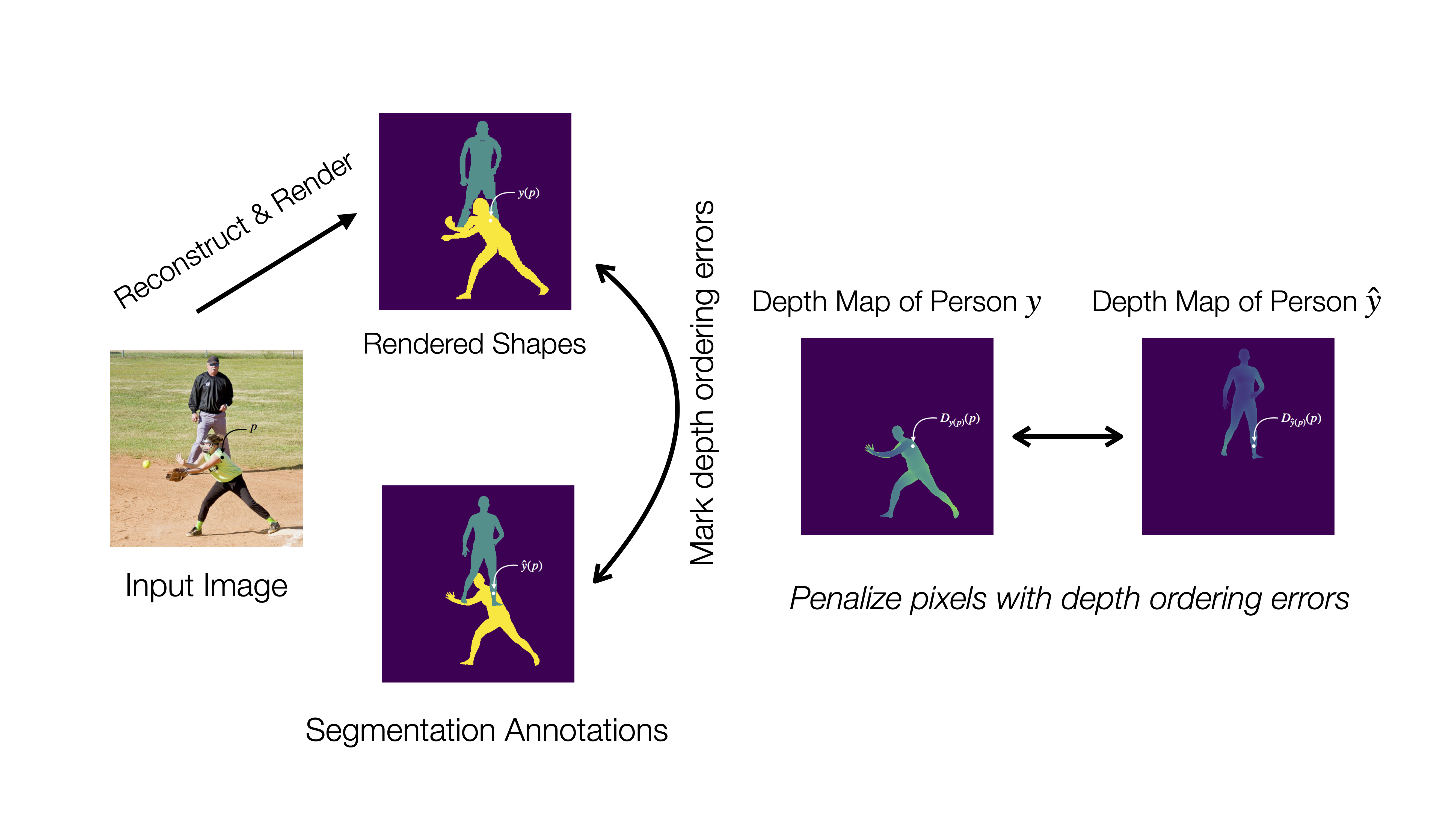
Second, we leverage available instance segmentation annotations and apply a depth ordering-aware loss that promotes the reconstruction of a scene whose rendering is consistent with the annotations.
Comparison with naive regression
Here we compare our method to naive regression approach that was trained without our geometric losses. Our method is able to predict the correct ordinal depth and avoid mesh collisions.
Additional results
Acknowledgements
NK, GP and KD gratefully appreciate support through the following grants: NSF-IIP-1439681 (I/UCRC), NSF-IIS-1703319, NSF MRI 1626008, ARL RCTA W911NF-10-2-0016, ONR N00014-17-1-2093, ARL DCIST CRA W911NF-17-2-0181, the DARPA- SRC C-BRIC, by Honda Research Institute and a Google Daydream Research Award. XZ and WJ would like to acknowledge support from NSFC (No. 61806176) and Fundamental Research Funds for the Central Universities (2019QNA5022). We also want to thank Stephen Phillips for the video voiceover.
The design of this project page was based on this website.
